Posted on June 1, 2021 by Rajesh Vinayagam
In the Second part of the article we saw Initial snapshotting of data from Azure CosmosDB for Mongo API to Atlas. Well this covers the scenario of getting the Initial data, but what happens to documents that are updated or newly inserted during migration? What if the client decides to have the ongoing changes replicated to Atlas for few days before he does application migration. Can we have the ongoing data available in Atlas? Yeah with CDC it should be possible.
Change Data Capture, is one of the common architecture pattern used for detecting changes as they are happening. This can be used for variety of use cases ranging from Cache Invalidation, ETL, Stream processing, Data Replication etc.
In this article we will see how Change feed works in Azure Cosmos DB for Mongo API. Some of the native capability like having an Azure Function Triggered when documents are inserted or updated is limited to SQL API. We will use the Change Stream API from Mongo and abstract the complexity of using the MongoDB Oplog from developers
To use change streams, create the Azure Cosmos DB’s API for MongoDB account with server version 3.6 or higher. If you run the change stream examples against an earlier version, you might see the Unrecognised pipeline stage name: $changeStream error.
Change Streams
Using Change Stream APIs Application are provided instant access to data changes (create, update, deletes) by subscribing at a database or collection level.
Design 1
A Custom Change Processor Application will be written to listen for any database change events and push them to scalable data ingestion platform like Kafka for further processing.
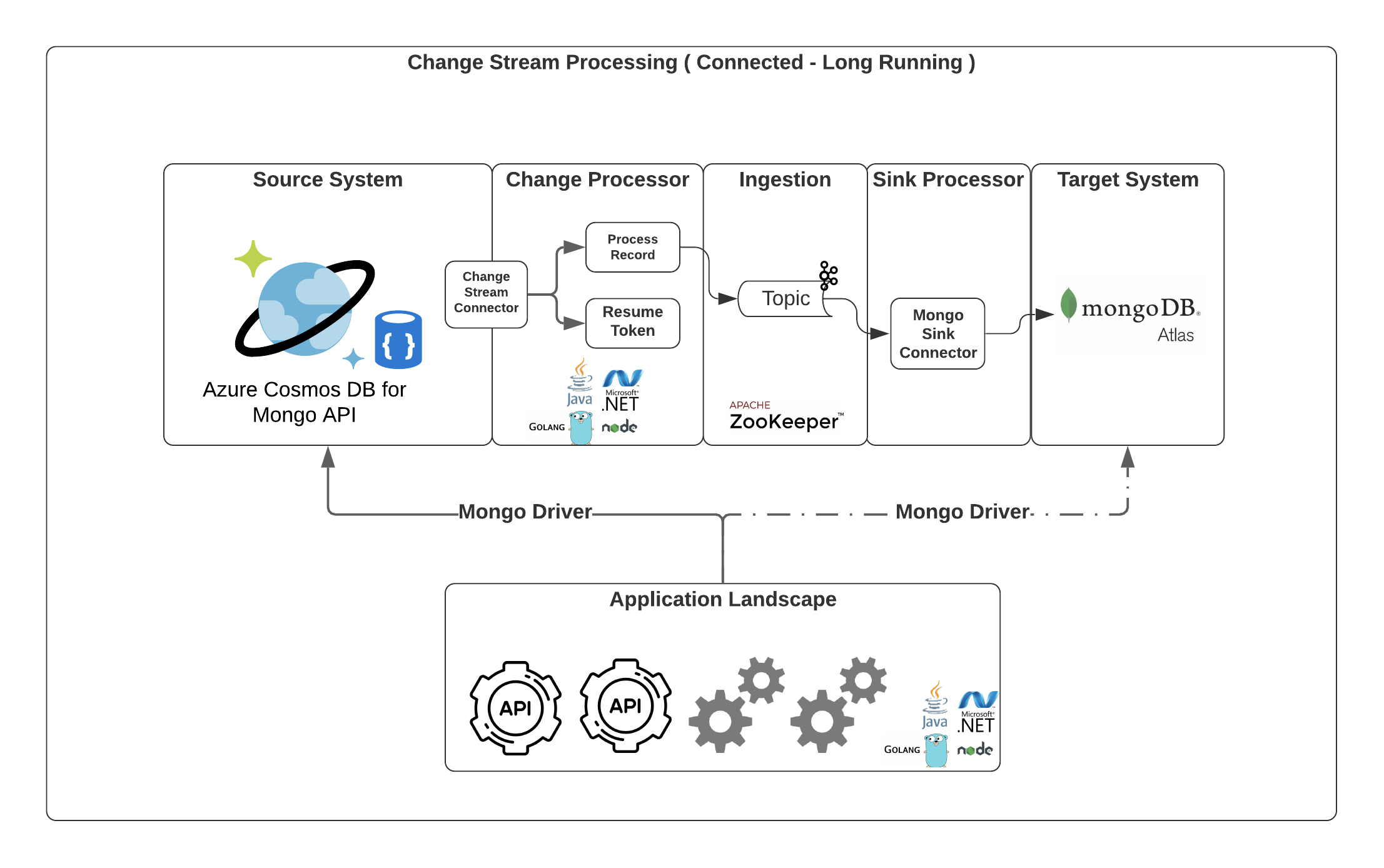
Later use MongoSink Connector for ingesting the message to Atlas.
The Application landscape( API’s, Services )can continue working with Cosmos as a data source and the data changes will be replicated to Atlas.
Once the user decides to switch over to Atlas, it could be as simple as switching the connection string.
With this design the user can migrate the data as and when it’s happening in the source, but this comes with the overhead of setting up the complex Kafka platform. With Kafka gaining popularity cloud providers are coming up with the managed Kafka platforms taking away the complex Kafka administration activities.
Design 2
Similar to Design 1, Change processor application will be responsible for capturing the changes as it’s happening but replication can be done in disconnected manner with Design 2, the overhead of Kafka platform can be avoided.
Change Processor application will dump the data as plain JSON files in batches and as needed we can leverage native mongoimport to move the changes to Atlas once a day or week( based on the required frequency).
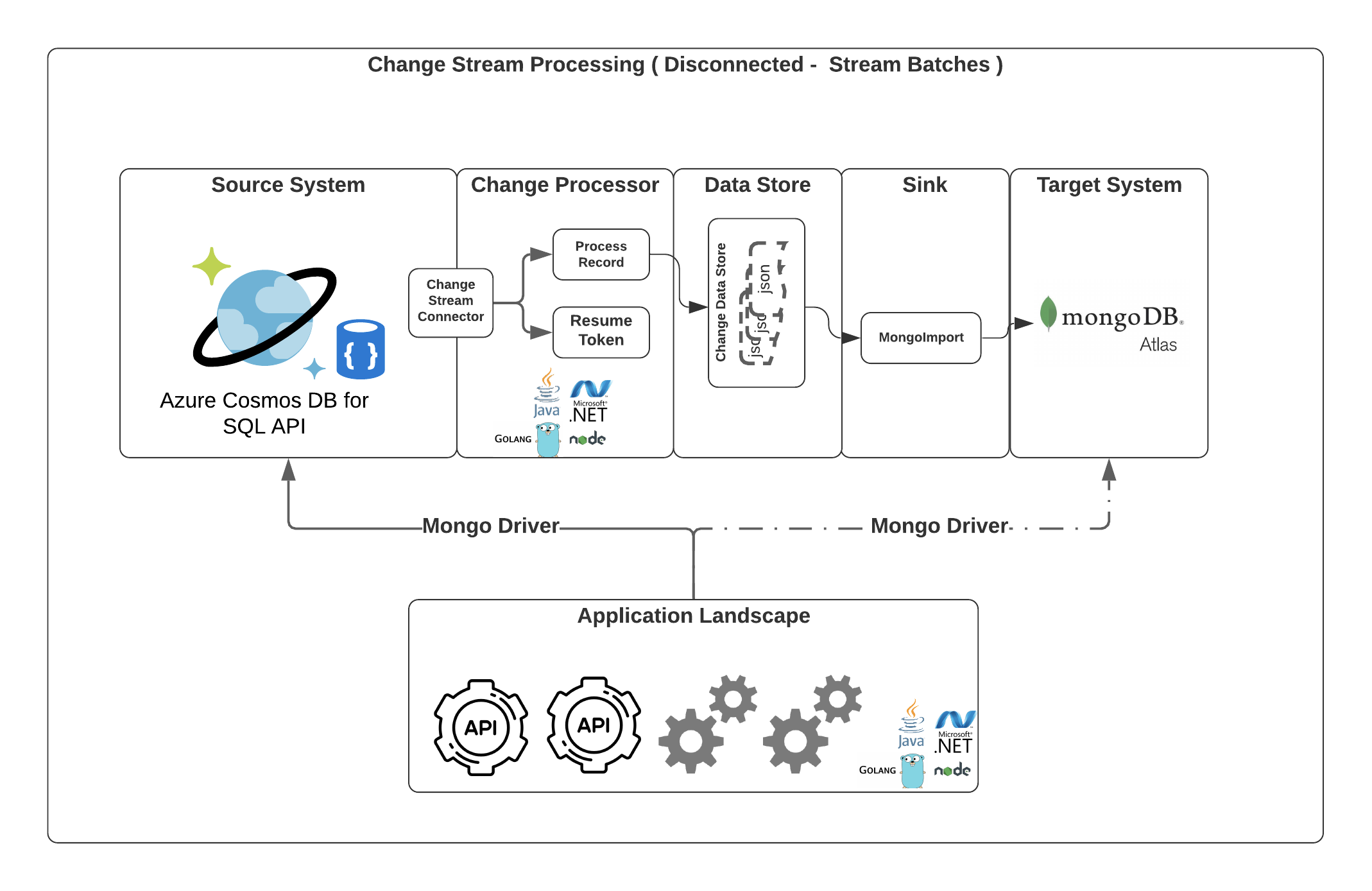
Change Processor App
Watch API will be used to subscribe to the change feed from a collection, database or deployment. The app later extracts the relevant information from the change event payload i.e. the document which was affected and pushes it to a Kafka Topic.
Resume Tokens are crucial to continue processing from any specific point. i.e., incase of failure or crash, we can use this token to resume the application from where it left and capture changes during this timeframe when it was not operating. It is similar to the concept of offset in Kafka.
In addition to this maintaining the history of resume token, will help us in processing the documents multiple times if required.
Limitations in Azure CosmosDB for Mongo API
- Currently Watch API is limited to only Collections.
- Deleted Documents cannot be tracked through CDC. As a workaround soft delete can be used instead.
Overall Design
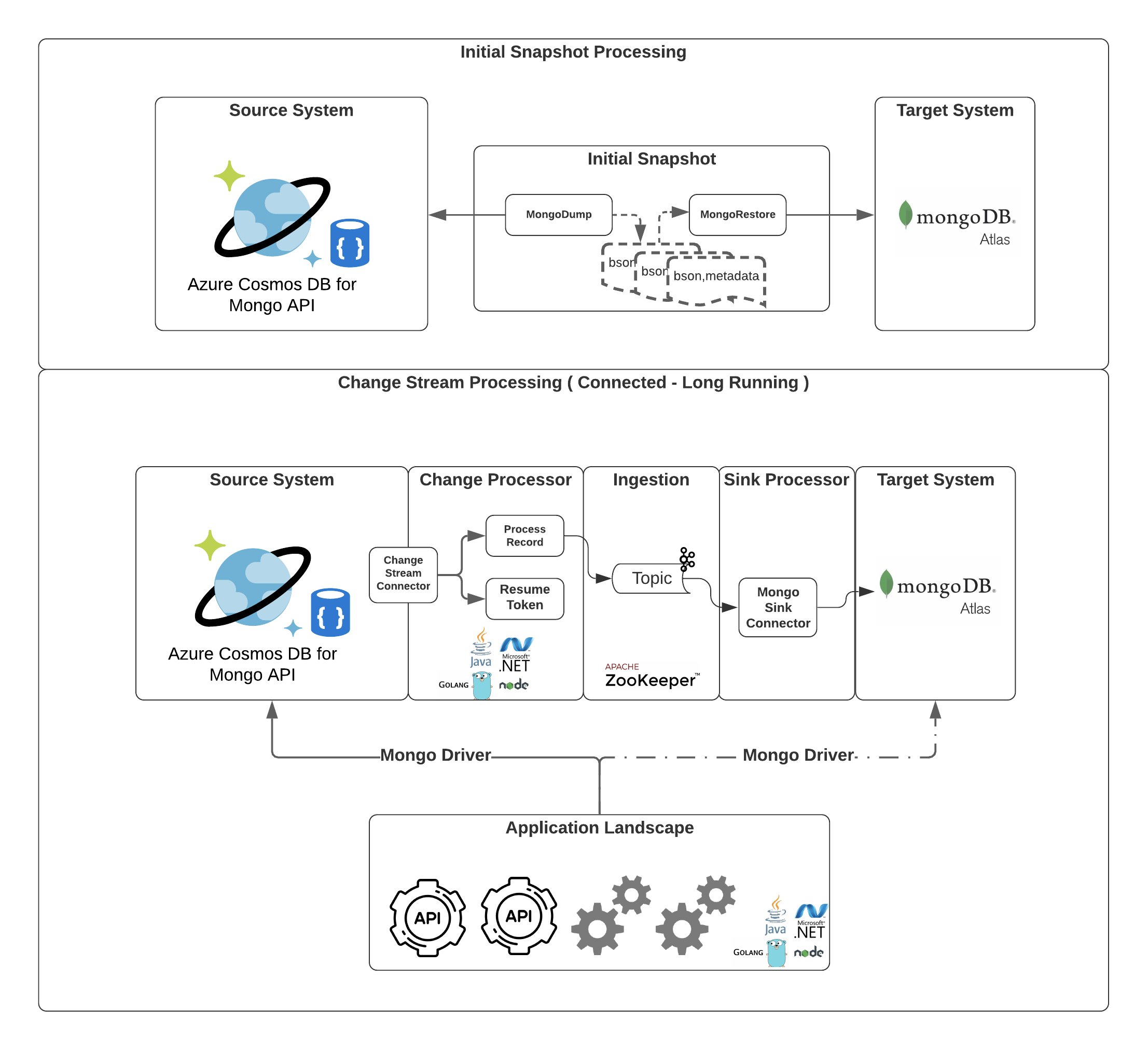
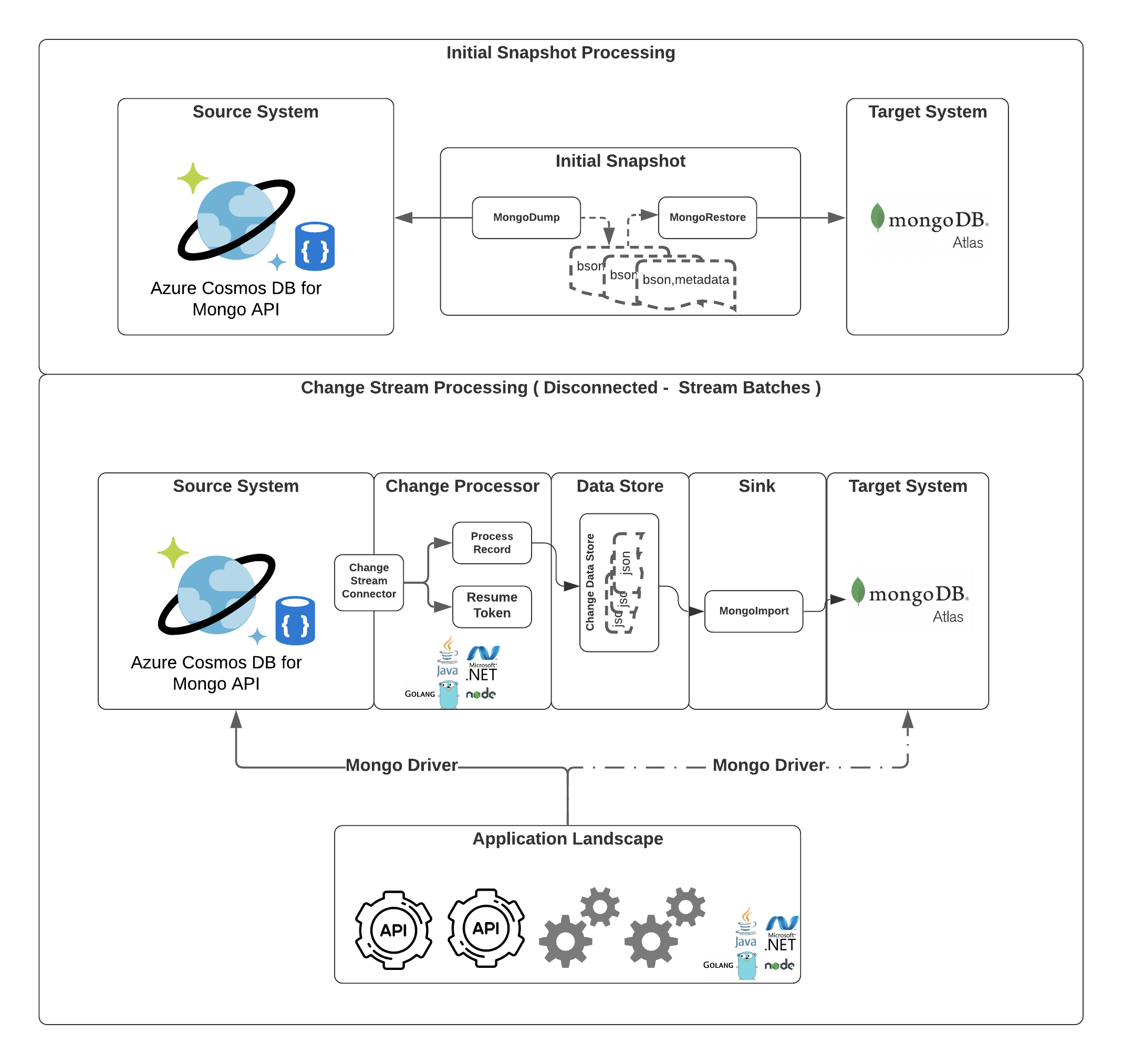
- Complete the Initial Snapshotting of data using mongodump and mongorestore.
- Capture any changes during Initial snapshotting and other changes until the application switch over using MongoDB’s Change Stream API either in a connected manner or disconnected manner depending on the needs
In the next article we will see how Spark can be leveraged for moving data from CosmosDB to Atlas.


