Scared of losing all your hard work in your systems due to errors like latency or CPU failures? This article explains a process called Chaos Engineering, a method of purposely “breaking things” in order to prevent overall failure and weakness. In order to have the strongest system, you need to be prepared for failure.
Posted on August 18, 2021 by Rajesh Rajagopalan
“Chaos does not mean total disorder. Chaos means a multiplicity of possibilities.”
The goal of every organization is to build a highly resilient and scalable system. Several have adopted a cloud-native, distributed, microservices architecture, with loosely coupled and independently scalable solution components. However, all distributed architectures have points of failure. Additionally, most programmers make false assumptions – documented as Fallacies of Distributed Computing – regarding distributed computing, which compounds the problem.
Maintaining complex and distributed systems while in production requires its own set of practices, mainly because of the unpredictability of such systems under stress conditions.
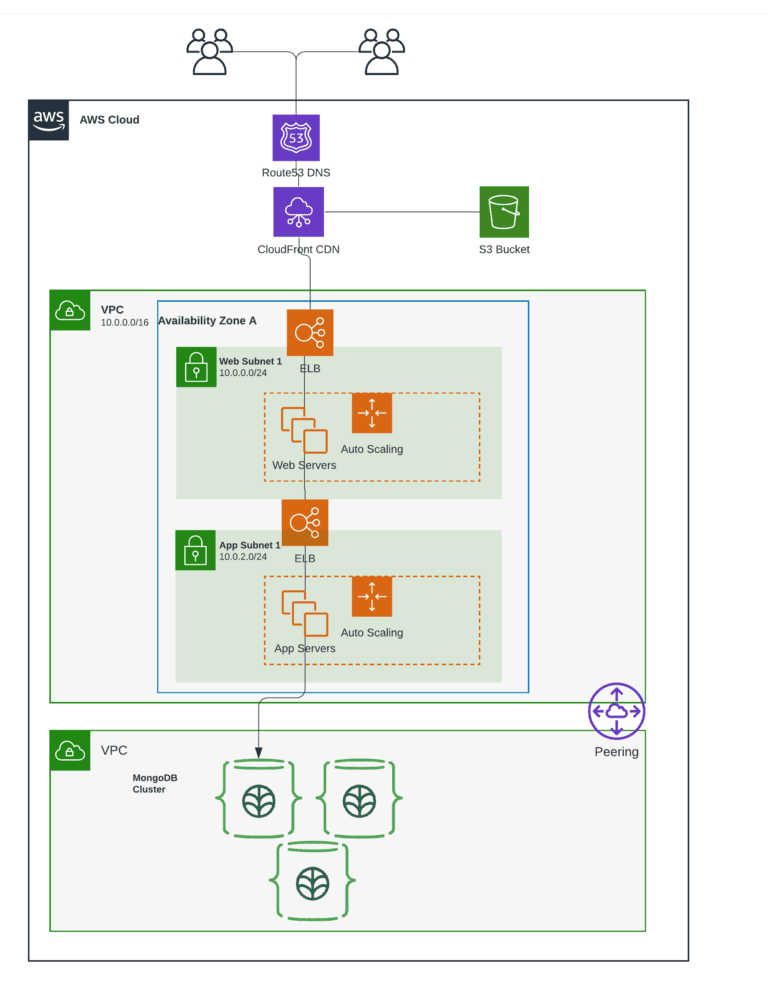
Let’s consider a simple web application architecture on AWS. While each layer functions as required, is resilient with auto-scaling, load balancing, and so on, the interactions between the components and real-world scenarios can result in unexpected behaviors. These in turn manifest as points of failure. Some are obvious such as infrastructure-level issues like AZ or regional failure, and others that are not as apparent. The latter could result in cascading and catastrophic failure. For instance, a retry storm in the service layer with too many retries and too large timeout values could result in service going down, in addition to the cascaded failure of the database layer.
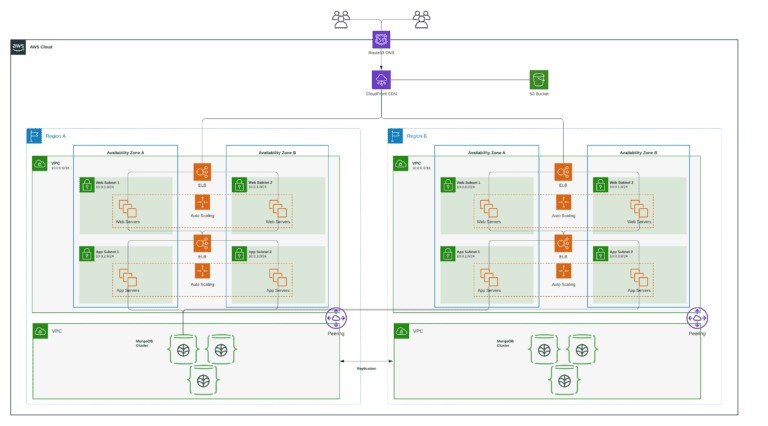
You can improve reliability with cross-availability zone and cross-region failover, automatic scalability and load balancing, etc, as in the architecture shown below. However, when you build a distributed architecture, the number of points of failure and real-world scenarios that could go wrong only increase.
Companies that prepare for chaos and real-world disruptions and unexpected situations fare better than those that don’t. You would be aware of many instances in the recent past, of large-scale disruption and outages that have affected several companies.
Microsoft Azure outage delays virtual premiere of Zack Snyder’s Justice League
AWS suffered a multi-hour, global outage on November 25, 2020, affecting 1Password, Adobe Spark, Autodesk, Flickr, iRobot, Roku, Twilio, The Washington Post, and Glassdoor
On December 14, 2020, Google Cloud experienced a widespread outage that interrupted services, including YouTube, Google Workspace, and Gmail
Netflix is one company that has survived many of these disruptions, with minimal impact.
Netflix had learned its lessons after the 2008 outage and redesigned its architecture to withstand such disruptions. Not only that, they have also perfected the art of breaking things in production to test how resilient their systems are, and improve on the weaknesses identified. They built the Simian Army and open-sourced them for others to benefit as well.
Amazon came up with the concept of Gamedays to simulate unexpected failures, test the resilience of systems, detect and fix any problems, and most importantly, train the operations team on how to handle such emergency situations.
In this blog, I look at what Chaos Engineering is, how can one start the journey toward putting it to production, tools required, solutions available, maturity models, and above all, how to develop a culture of building resilience into products and continuing to improve it.
Chaos Engineering in practice
“Chaos Engineering is a disciplined approach to identifying failures before they become outages. Using thoughtful experiments, you break things on purpose to learn how to prevent outages and build more resilient systems.”
Instead of waiting for an outage to happen, you meet the problem head-on. You literally “break things on purpose” to learn how to build more resilient systems. It is similar to a fire drill or a vaccine shot. Chaos Engineering / Fault Injection Testing (FIT) is a tool used to build immunity in our systems by systematically injecting harm (like latency, CPU failure, or network black holes) in order to find and mitigate potential weaknesses.
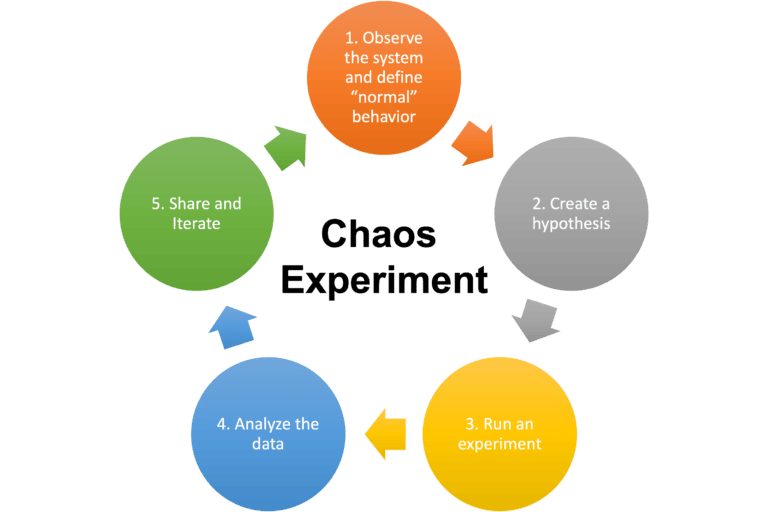
A typical Choas Engineering process has the following:
Defining steady-state / baseline metrics for your system. These metrics indicate what the normal behavior of your system is.
What do you need before you can start?
At a minimum, Observability tools need to be in place
Applications instrumented for monitoring and measurement of various metrics
Baseline metrics that determine the reliability of your system. Typically these fall into one of the following categories:
Infrastructure Monitoring Metrics
Alerting and On-Call Metrics
High Severity Incident (SEV) Metrics including MTTD, MTTR, and MTBF for SEVs by service
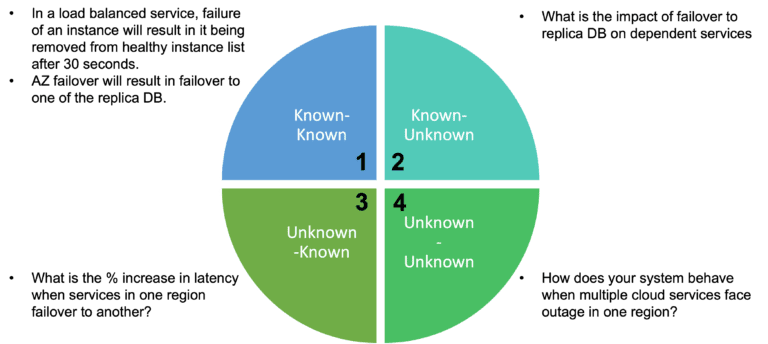
Create a hypothesis for the potential points of failure that will break this steady state. How to build the right hypothesis?
Think about “what could go wrong?”
By systematically asking a series of questions about your services, infrastructure, and real-world events that impact your system, you can identify potential weaknesses.
These potential weaknesses become the basis for the hypothesis you would create for chaos experiments.
Involve all stakeholders in coming up with a hypothesis.
Run experiments / Failure Injection Testing (FIT) to introduce variables that reflect real-world events like servers that crash, application failure, network latency issues, etc. These experiments, among other things, should:
Start small
Choose and test one hypothesis at a time
Limit the “blast radius”
Have a fallback plan
Analyze the data and develop improvements before that behavior manifests into a larger system failure.
Improvements could take the form of:
System and architecture enhancements
Bug fixes
Automated process to scale the infrastructure etc.
Measure and learn:
Time to detect a problem (MTTD)
Time to recover from a problem (MTTR)
Operational processes that kicked in for notifying stakeholders, how the response process worked, etc.
Share the results with the larger group and iterate.
“The harder it is to disrupt the steady-state, the more confidence we have in the behavior of the system.”
Practical Chaos experiments
We will explore running chaos experiments on an architecture like the one we saw earlier, using Gremlin to run Chaos experiments on the services layer (a Spring Boot application deployed on a VM) as well as on MongoDB.
Setup will include a typical MEAN stack application deployed on AWS.
Deploying Angular app on load-balanced AWS EC2 instances behind an Elastic Application Load Balancer. Each instance is deployed in a different Availability Zone for higher availability.
Deploying NodeJS/ExpressJS backend service on load-balanced AWS EC2 instances behind an Elastic Application Load Balancer. Each instance is deployed in a different Availability Zone for higher availability.
(Refer this Git repo for both client and server-side code: https://github.com/rrajesh1979/sample-ce-project.git)
Setup MongoDB Atlas database.
We will use Gatling to simulate a test scenario (Refer this Git Repo. While I use a load testing solution here, it’s essentially testing the reliability of the system under load). This will generate a steady load increasing in stages. The test will run for 60 seconds generating about 16k requests for the home page that displays a list of books available in the MongoDB Atlas database.
Setup Gremlin account and install agents on the EC2 instances.
Experiment 1:
We will follow the steps we discussed earlier:
Baseline metrics: Success response for all 16k requests.
Hypothesis: AZ failure or loss of one of the load-balanced web servers will result in traffic being re-routed to the healthy instance.
Run experiment: Ran a simple “Process Killer” attack from Gremlin to simulate the above scenario. This will kill the HTTPD process in one of the web server instances.
Analyze results: The ALB recognized the unhealthy web server instance and started re-routing traffic to the healthy instance. However, the result showed 42% of requests failing. Upon analyzing, the health check was set up to check every 30 seconds. By that time, traffic continued to flow into the unhealthy instance – resulting in a 42% failure rate.
Iterate: Optimized the ALB health check configuration and re-ran the test.
Iteration 2 results: This iteration showed much better results. The failure rate dropped from 42% to 8%.
The next step would be to further optimize the failure rate. What are the options for the Web layer?
Use S3 static hosting. S3 provides 11 9s availability
You can further improve availability by configuring failover at Route 53 level. This will help avoid issues like the one described earlier of how a region failure and subsequent impact to S3 service in that region can be mitigated.
That is not all. Organizations are now looking at Multi-cloud solutions for fallback and risk mitigation mechanisms when there is an outage across the entire cloud platform.
Experiment 2:
While we saw how we can improve the availability of your application by better configuration at the infrastructure layer level. How about what can we do at the application layer level to improve availability. How can we identify potential weaknesses?
Let’s consider the application layer in the same setup as above. NodeJS based application server running on multiple availability zones behind an ALB for failover and higher availability.
Baseline metrics: Success response for all 16k requests.
Hypothesis: AZ failure or loss of one of the load-balanced app servers will result in traffic being re-routed to the healthy instance.
Run experiment: Ran a simple “Process Killer” attack from Gremlin to simulate the above scenario. This will kill the “node” process in one of the app server instances.
Analyze results: The ALB recognized the unhealthy web server instance and started re-routing traffic to the healthy instance. We had optimized the ALB configuration already. Hence, in this run we had 10% of requests failing.
How can we improve the failure rate?
Reducing the health-check interval further will be counterproductive.
The solution likes in the Web Layer.
Implement retries with exponential backoff: The web layer in the above instance did not have a retry mechanism in place. Any temporary downtime or transitionary network issues in the downstream services layer would result in a significant impact on the end-user experience.
Next Iteration
After implementing the retry mechanism in the web layer, the failure rate went down to less than 1.5%.
The number of retries and retry intervals need to be optimized further to improve upon the failure rate to be closer to 0%.
Experiment 3:
Finally, let’s look at the database layer. In our case, we have MongoDB Atlas which is a managed DBaaS solution. What are the potential weakness of the DB solution or connectivity to the database? How can we identify and mitigate them?
From a MongoDB Atlas standpoint, we can run similar experiments. Let’s consider the following
Hypothesis: Primary failover will result in re-election and one of the secondary nodes being promoted to Primary. Data written should be durable.
Experiment:
Option 1: MongoDB Atlas provides a way to simulate this experiment right from the console by triggering a Failover
Option 2: Generate a Blackhole attack using Gremlin
Observations
Data durability: With w=1 writes are not durable and are lost with new Primary election
Failure rate: High % of failure during the election process without retries in place
Improvement in code
Data durability is guaranteed by using “writeConcern=majority”
Reduced failure rate by implementing retries for transitionary problems. This can be easily done by a simple setting in the connection configuration “retryWrites=true”
For further improving failure rates
Implement a dead-letter queue and exception handling process when the problems are longer than transitionary. For example, the election process takes longer.
These experiments demonstrate how we can run tests in a structured manner to identify weaknesses in our system and improve upon them. While this test focussed on infrastructure configuration weakness, we can run similar tests to identify weakness at various layers, including the application, towards improving the reliability of our system.
Gremlin is a Chaos testing as a service solution that allows you to simulate various types of attack vectors that will impact our systems. To call out a few:
Resource Gremlins to simulate resource starvation
CPU load for one or more CPU cores
Memory
IO
Disk
State Gremlins to introduce chaos into your infrastructure
Shutdown
Process Killer: Kills the specified process, which can be used to simulate application or dependency crashes
Time Travel: Changes the host’s system time
Network Gremlins to simulate the impact of lost or delayed traffic to your application.
Blackhole: Drops all matching network traffic.
Latency: Injects latency into all matching egress network traffic
Packet Loss: Induces packet loss into all matching egress network traffic.
DNS
There are other tools and practices that you can bring into practice as you can see in the next section.
The key here is to follow the process discussed, and consistently apply it across critical systems, and keep iterating to improve the reliability of systems.
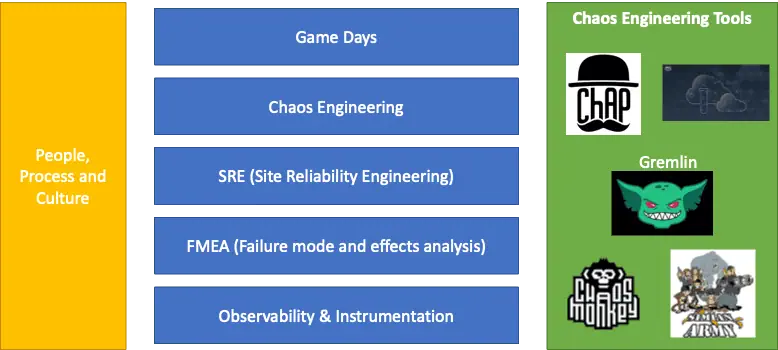
Tools and practices
GameDay
Gamedays are like fire drills – an opportunity to practice a potentially dangerous scenario in a safe environment.
A Gameday tests your company - from engagement to incident resolution, across team boundaries and job titles. It verifies the system at scale, ultimately in production.
A term coined by Jesse Robbins when he worked at Amazon and was responsible for the availability.
Tools: There are a number of tools available. You can pick based on your ecosystem of solutions. Few notables ones from my experience
Netflix Chaos Monkey and the Simian Army – one that started it all.
Netflix ChAP and FIT – While Chaos Monkey and Chaos Kong help experiment on infrastructure reliability, FIT and ChAP help inject failures into microservices and identify weaknesses.
AWS Fault Injection Simulator helps you to perform controlled experiments on your AWS workloads by injecting faults and letting you see what happens.
Gremlin – was launched as an enterprise Chaos Engineering solution by Kolton Andrus who built FIT at Netflix, and by Matthew Fornaciari.
People, Process, and Culture
While you can have sophisticated tools, you also need to have Incident Response teams and processes built to handle failures or events when they occur.
You need to build a culture of adopting reliability engineering across the development life cycle. This is not a one-time event.
I would like to call out two other related practices that also focus on building reliable systems – FMEA and SRE. How are these related to Chaos Engineering?
FMEA is a decades-old method for proactively reviewing as many components, assemblies, and subsystems as possible to identify potential failure modes in a system and their causes and effects
It was developed in the 1950s by reliability engineers in the U.S. military to study problems that might arise from malfunctions of military systems. An FMEA is often the first step of a system reliability study.
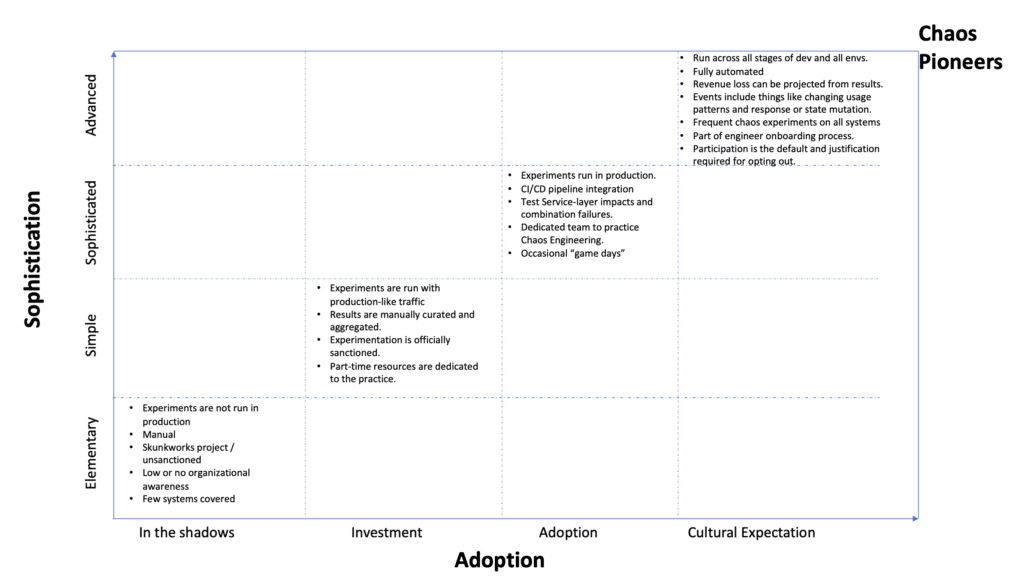
While you can start practicing Chaos Engineering in your organization, how can you mature it. What are the various levels of maturity?
Chaos Maturity Model (CMM) can be used to determine the current state of the process in an organization. CMM can be measured across two metrics – Sophistication and Adoption. You need to progress on both metrics to have a mature Chaos Engineering practice. Sophisticated tools and processes are required to ensure you don’t cause any unintended harm. You need adoption across all critical systems, test a variety of vectors as well as build it into your development life cycle and culture. Having adoption without sophistication is a dangerous proposition. While having sophisticated tools and processes without adoption will be a wasted investment.
It is not just for Netflix or Amazon
When you talk about Chaos Engineering within an organization, the general response is one of:
We are neither Netflix nor Amazon
This sounds great, but our organization has more pressing needs
Our systems don’t require the complexity of another process such as Chaos Engineering
While some of the hesitation and skepticism are understandable, when you have other problems to deal with, it’s the culture of building resilient systems that is most important. Chaos engineering is but one tool in the arsenal.
In 2016, IHS Markit surveyed 400 companies and found downtime was costing them a collective $700 billion per year. And Gartner estimates downtimes cost companies $300,000 per hour. For example, Amazon.com would lose $13.22 million dollars for a single hour of downtime.
While you might see this as a daunting practice at the beginning only suitable for high-tech companies, the payoff by adopting Chaos Engineering can be significant. The intangible benefit of avoiding downtime during peak season and building confidence in your customers about your system cannot be easily quantified.
“Chaos was the law of nature; Order is the dream of man.”
Subheader 1 Text Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna.Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna.
Subheader 2 Text Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna.
Subheader 3 Text Lorem Ipsum Dolor Sit Amet, Consetetur Sadipscing Elitr, Sed Diam Nonumy Eirmod Tempor Invidunt Ut Labore Et Dolore Magna Aliquyam Erat, Sed Diam Voluptua. At Vero Eos Et Accusam Et Justo Duo Dolores Et Ea Rebum. Stet Clita Kasd Gubergren, No Sea Takimata Sanctus Est Lorem Ipsum Dolor Sit Amet. Lorem Ipsum Dolor Sit Amet, Consetetur Sadipscing Elitr, Sed Diam Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna.
PeerIslands combines proven expertise with an efficient platform, optimized for MongoDB. Their collaborative approach, top-notch experts, and focus on customer fulfillment