Posted on April 18, 2022 by Rajesh Rajagopalan
MongoDB has been the de-facto document database that has been used by many across domains and use-cases. Apart from key capabilities such as high availability, security, ACID compliance, the JSON like document data model that maps directly to how you represent data in code leads to high developer productivity and flexible + evolutionary data models. This resulted in MongoDB becoming a go to platform for developers in most domains and use-cases including eCommerce, telecom, financial services, healthcare.
When it comes to Time Series data, the requirements are very different. MongoDB 5.0 added native Time Series capabilities, enabling developers to use the same tools and frameworks they are familiar with.
In this blog, I look at typical characteristics of time series data, what are the requirements from a database system that can handle time series data as well as a summary of my experiments with various capabilities that MongoDB provides to meet these requirements.
TLDR
- There is an explosion of time series data being generated across domains ranging from Healthcare, eCommerce, FinTech, IoT among others.
- TSDBs are optimized for high high rate of data ingestion, higher compression% and low latency retrieval of data for time series data analysis.
- MongoDB introduced native time series collections with the 5.0 release.
- Before 5.0, developers had to managed time series data using fixed or time series bucket pattern. MongoDB time series collections automates much of data organization into buckets and while maintaining faster retrieval times.
- Based on my experiments, you can see in the sections below, how MongoDB native time series collections provides capabilities required to handle time series data.
- Data storage footprint that is several times smaller compared to normal collections – for time series data
- Clustered indexes optimize index storage and performance
- Specialized time series analytical query functions such as $setWindowFields that perform several times faster
- Capability such as $densify and $fill to handle missing data with ease
- Automatic purge of older data. Archival of data using Atlas online archive and
- internals of how MongoDB handles storage and retrieval of time series data
MongoDB is continuing to rapidly release new features to improve on the above capability. It will be interesting to see what MongoDB 6.0 has to offer later this year.
Characteristics of Time Series data
In mathematics, a time series is a series of data points indexed (or listed or graphed) in time order.
- Univariate or Multivariate time series data: Univariate time series have a single data point changing over time — for example stock price for a ticker. Multivariate time series have multiple data points changing over time — for example CPU, Memory, IOPS usage reported by a server over time.
- Polymorphic: Each reported data point can be different from previously reported data point. For example CPU% may be reported every second. However the disk utilization% may be reported only hourly by the same reporting sensor or agent.
- Velocity: High velocity of new data available every other millisecond or nanosecond from the sensor based on the granularity required for the use-case.
- Volume: Higher granularity combined with millions and billions of reporting entities result in billions and trillions of data points every hour that needs to be stored and processed.
- Out of order data: Time series data is not always ingested in order. Many IoT sensors in the field report back when they come online or have network connectivity. This invariably leads to out of order data.
- Irregular: Reporting and logging data is usually secondary priority compared to a mission critical function that any device performs. Data is reported on a best case basis. Having large gaps in data is not unusual.
- Immutable and append-only in most cases: Time ordered data is received at regular intervals and you generally want to record the data as a new entry irrespective of the change for future analysis.
- Columnar in nature: Limited variance one data point to another. For example, only the temperature data reported may change second to second. Rest of the sensor metadata remains fairly constant.
Time series data are used in numerous use-cases ranging from predicting weather, heights of tides, stock prices to financial fraud. It is used in any domain of applied science and engineering which involves temporal measurements. You generally look for
- Trend
- Seasonality
- Outliers
How are (Time Series Database) TSDBs different from traditional relational or NoSQL databases?
Time series databases (TSDBs) are optimized for storing and retrieving large volumes time series data. Metrics data about a server, IoT sensor data, eCommerce data, log data and other could run into billions and trillions of data points over a period of time. TSDBs should be optimized for the following.
- Queries: Typical queries are analytical in nature. Time Series Analytics such as year-over-year comparison, moving average over period of time and so on.
- Specialized indexes: Unlike normal datasets, time series data requires specialized indexes to speed up access to specific date ranges. Especially for typically analyzed time ranges such as last hour, last day, etc.
- Compression: Utilize compression algorithms to effectively manage storage of high volume of data while maintaining performance.
- Archive older data easily: Most analysis requires recent data. For others that require long term data access can tolerate slower response times. TSDBs should allow users to easily purge or archive older data points.
- Interpolation: As time series data can be irregular in most cases, TSDBs should provide interpolators that can fill missing data points.
- Window functions: Query capability to process out of order data, late arriving data.
- Time based query functions: Specialized query functions for various temporal operations such as moving averages, YOY comparisons among others.
MongoDB Time Series database — before 5.0
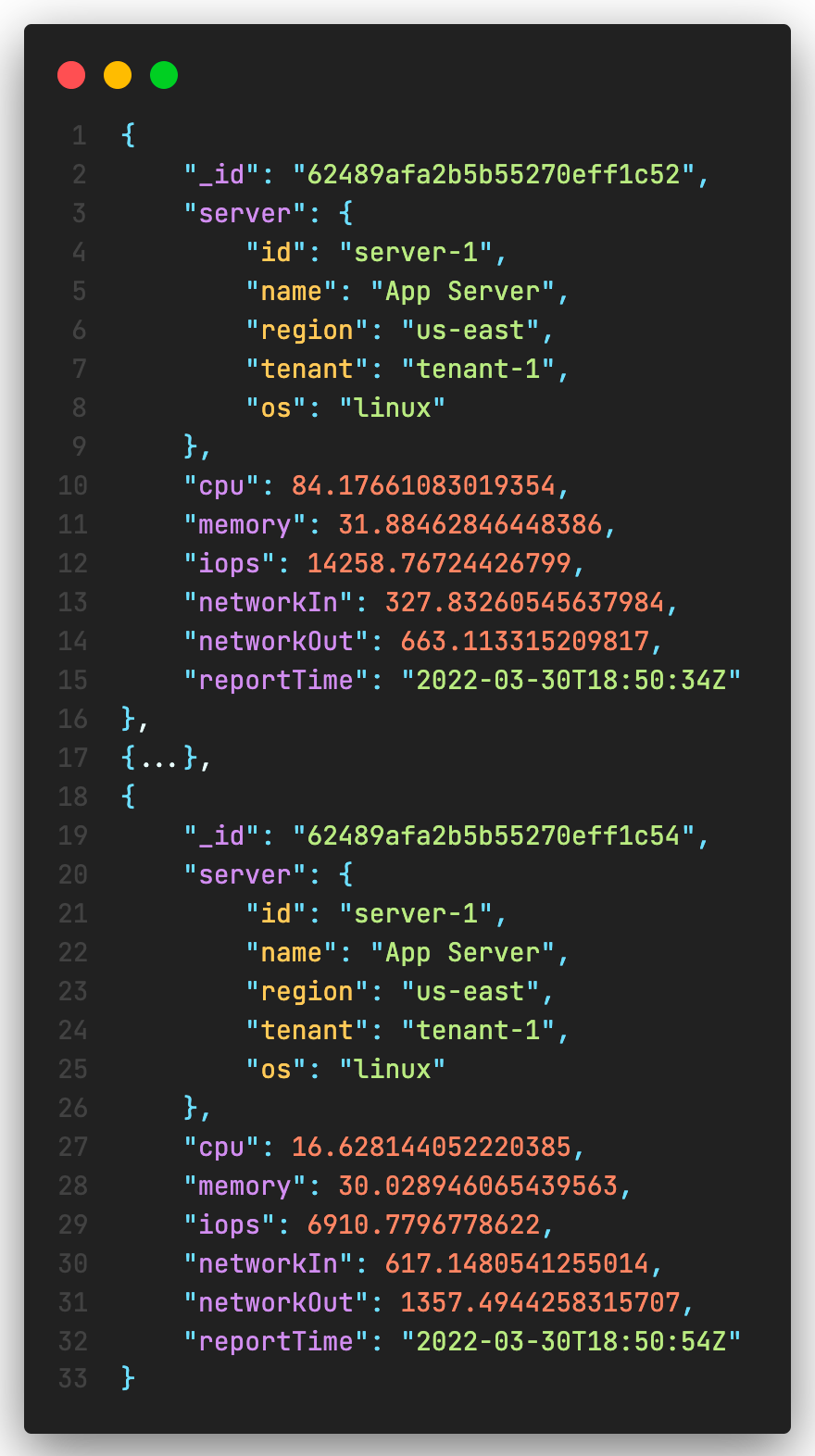
Before 5.0 release of MongoDB, you could store each individual data point as a separate data point as shown below.
Or use a bucket pattern and bucket data as shown below.
- Time based buckets
- Fixed size buckets
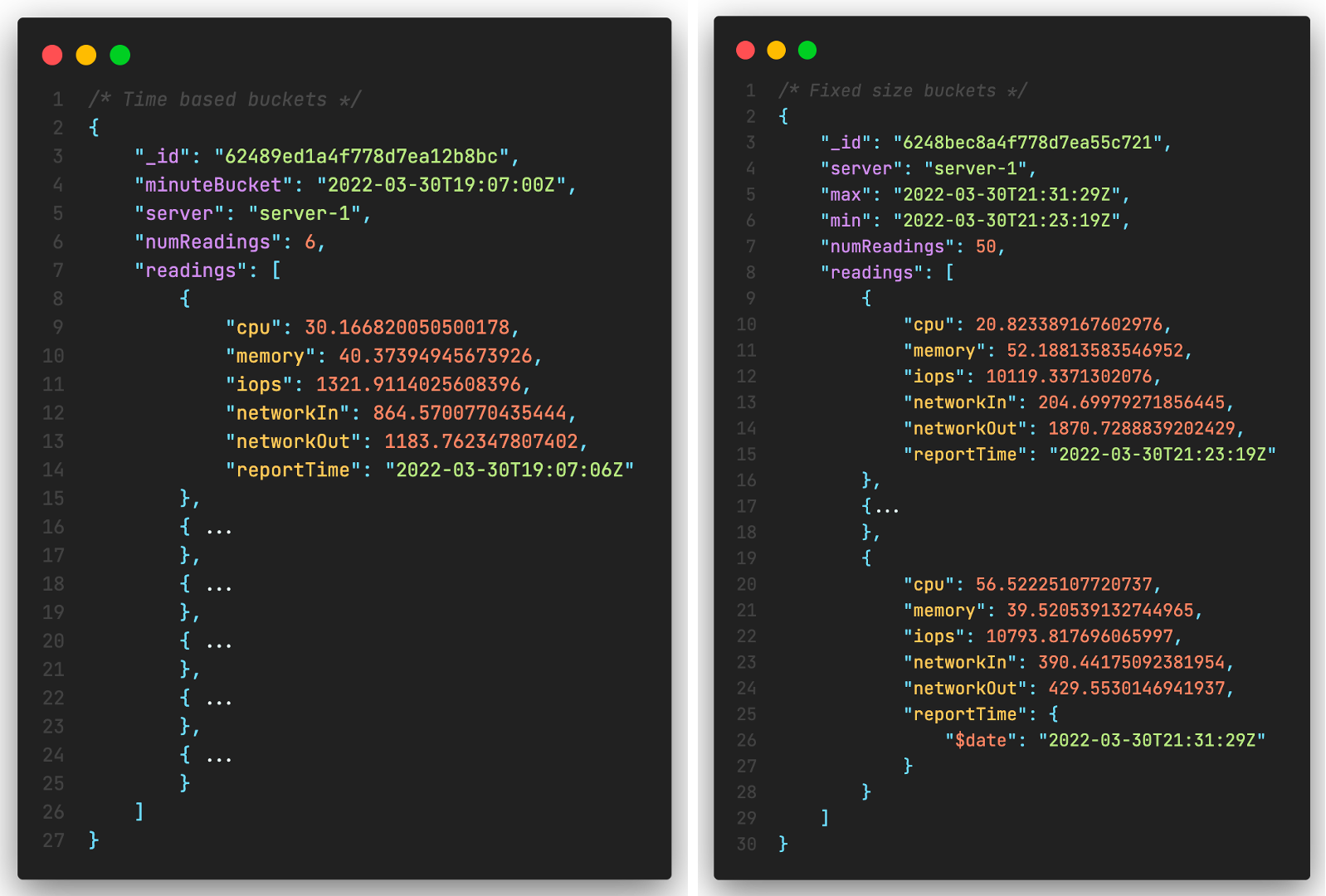
However these approaches come with limitations. To call out a few of them
- Significantly higher data and index storage compared to specialized TSDBs
- No specialized temporal functions for faster data access
- Indexing is not efficient for time series data
- Overhead of management of buckets
And many more.
MongoDB 5.0 Native Time Series database
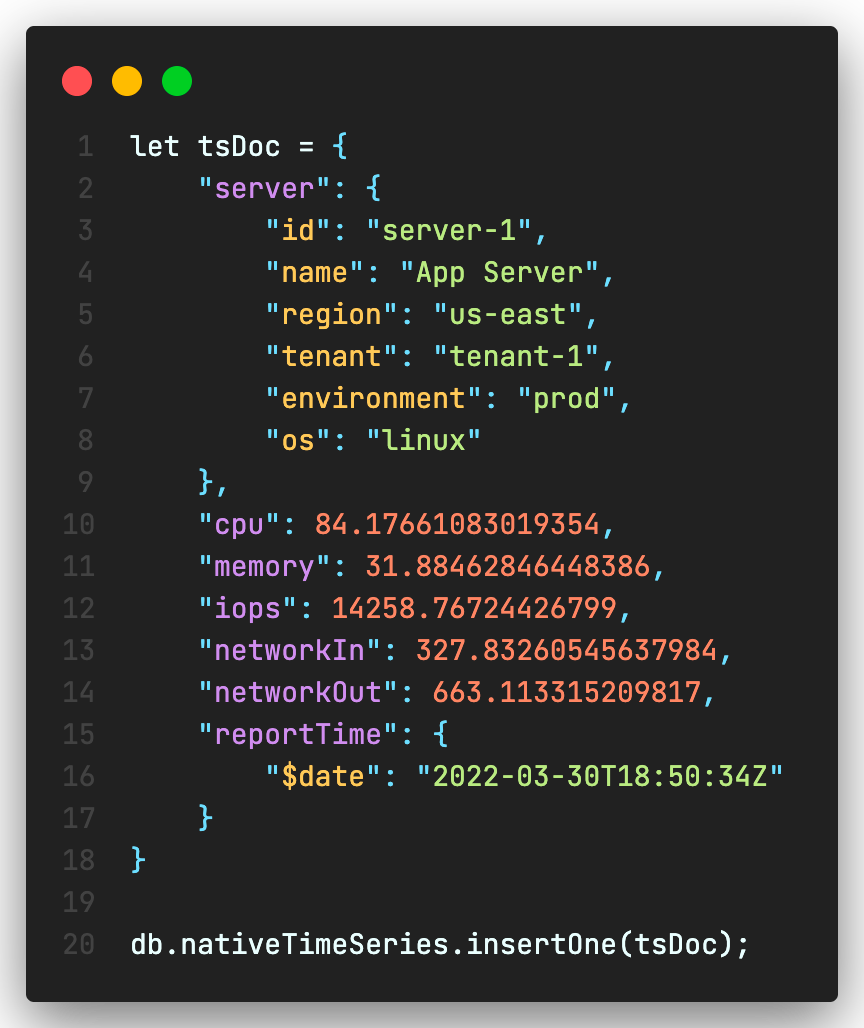
MongoDB 5.0 introduced native time series data. You can create a time series collection as follows

timeField: is the field containing the timestamp attribute in each data point.
metaField: contains the metadata for the reported data point. This can be a single attribute or a nested document with multiple fields. The metaField typically does not change over time.
granularity: can we set to “seconds”, “minutes” or “hours” based on rate of ingestion. This helps MongoDB automatically bucket the data.
expireAfterSeconds: specifies the TTL (Time to Live) in seconds after the document is created. Expired documents are automatically purged by MongoDB.
Once you create the time series collection, insert works like any other collection.
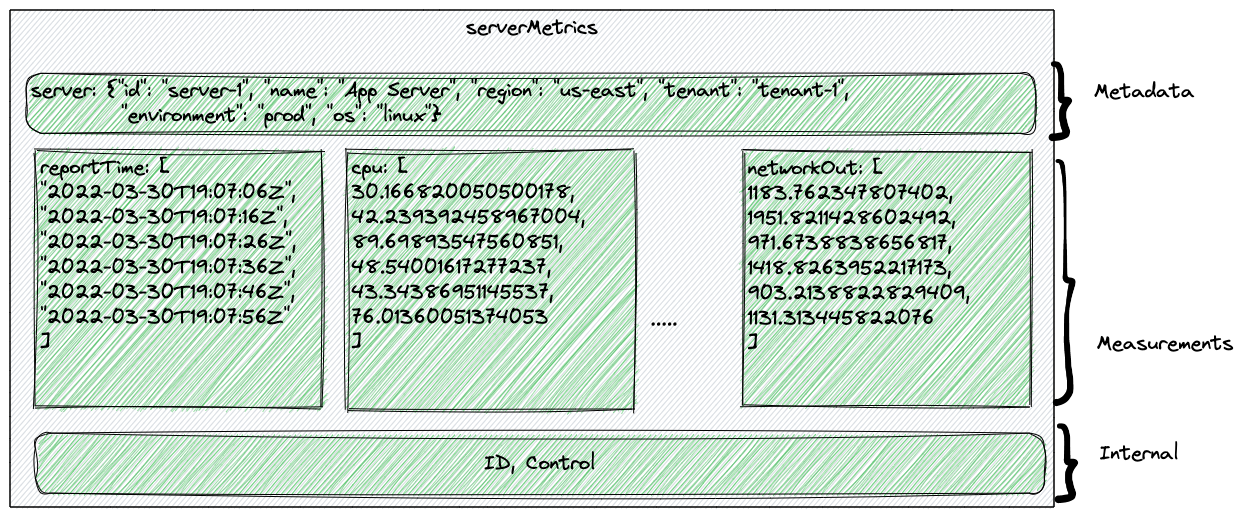
MongoDB Time Series internals
Internally the data is represented as follows. The metadata is only recorded once per series, the time and measurement fields stored and accessed in columnar fashion and finally some internal data.
Based on the granularity — multiple buckets are automatically created for storing data.
What happens when you query a time series collection? How does MongoDB retrieve data that is stored in above structure?
Let’s take a look at the explain plan for a query on time series collection.

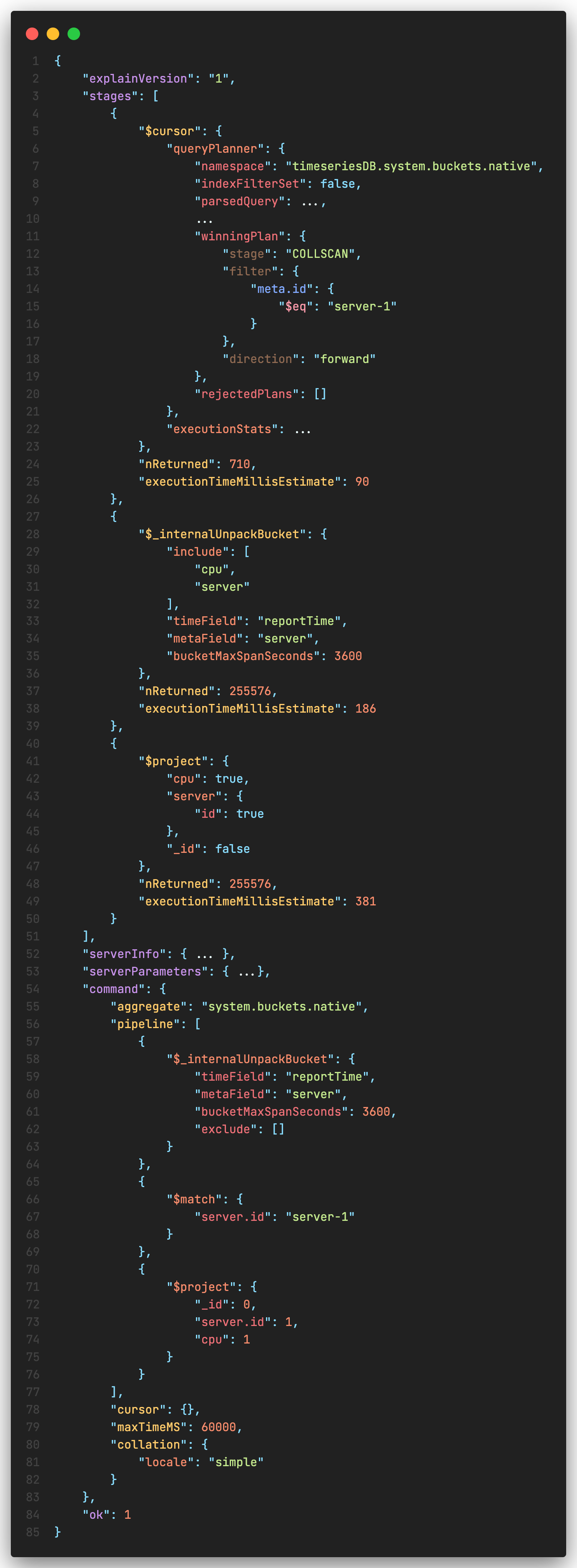
A closer look at the stages throws light on how MongoDB internally handles the query
- Cursor to retrieve all “buckets” of data that match the query criteria
- $_internalUnpackBucket is an internal MongoDB aggregation pipeline stage which unpacks the buckets of data into normal set of documents that can be used in subsequent stages.
- While unpacking, only the required measurements are retrieved and not the entire set. This can significantly reduce the amount of resourcing and processing power used at scale.
- Project stage
You also notice the “namespace” is different from the collection you queried. Where did this come from?
MongoDB time series collections are writable non-materialized views on internal collections that automatically organize time series data into an optimized storage format on insert.
As a result, the queries unpack data from the internal collections for usage.
Let’s take a look at how the data is stored in the “internal collection”.
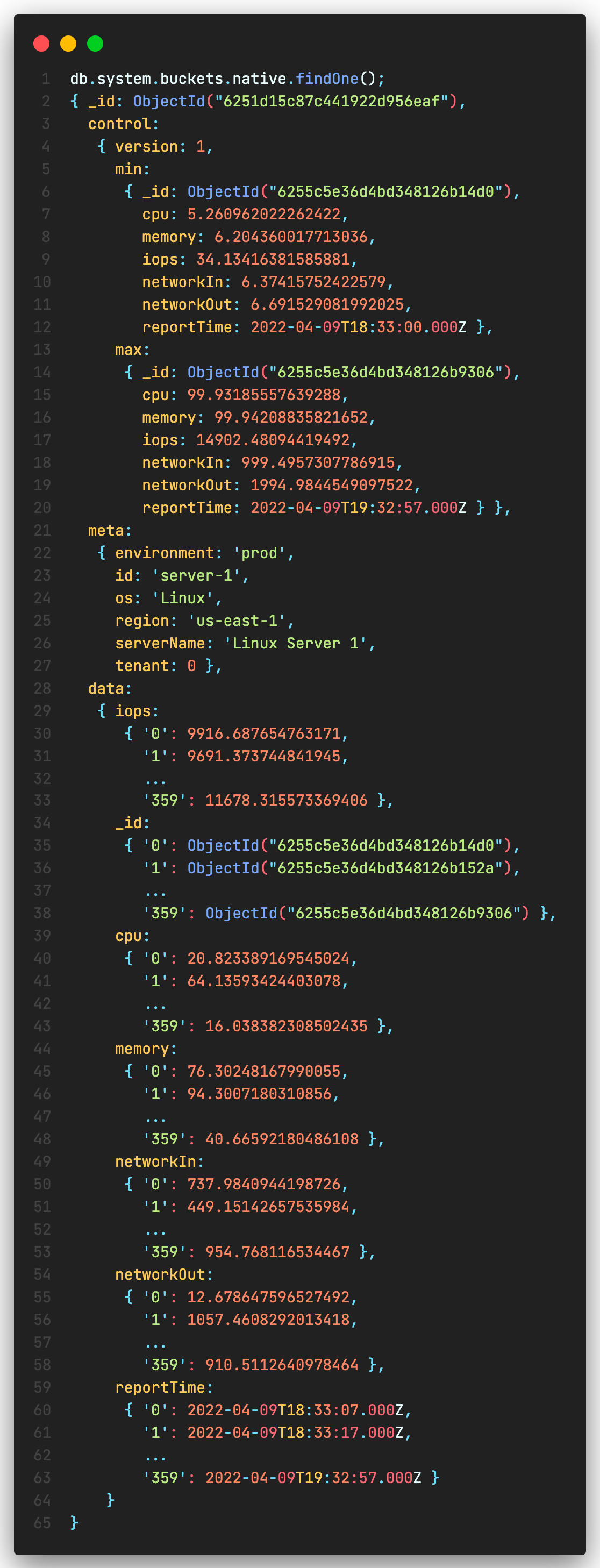
- The meta data is stored only once
- Measurements are stored in columnar fashion
- There is a control block that has min and max values readily available
You can create secondary indexes as required. For example I created the following secondary indexes to be able to search by just server.id or search by server.region.
More on indexes later.
MongoDB native time series vs standard collection
How does native time series collection compare against standard collection?
What is more efficient?
What query capabilities does native time series provide?
My setup was as follows.
- M30 with 128GB storage.
- Data inserted through a Java program running on a VM
- Connectivity to Atlas via VPC peering
Note: This is in no way a performance test nor tuned to extract the best performance. This is for the purposes of doing a quick comparison only.
Rate of ingestion
Native Time Series collection demonstrates it is roughly 70% faster compared to normal collection. To make the comparison consistent, both collections had an index of {server.id: 1, reportTime: 1}.
I also tested against time series collections of various time granularity to see how they behave.

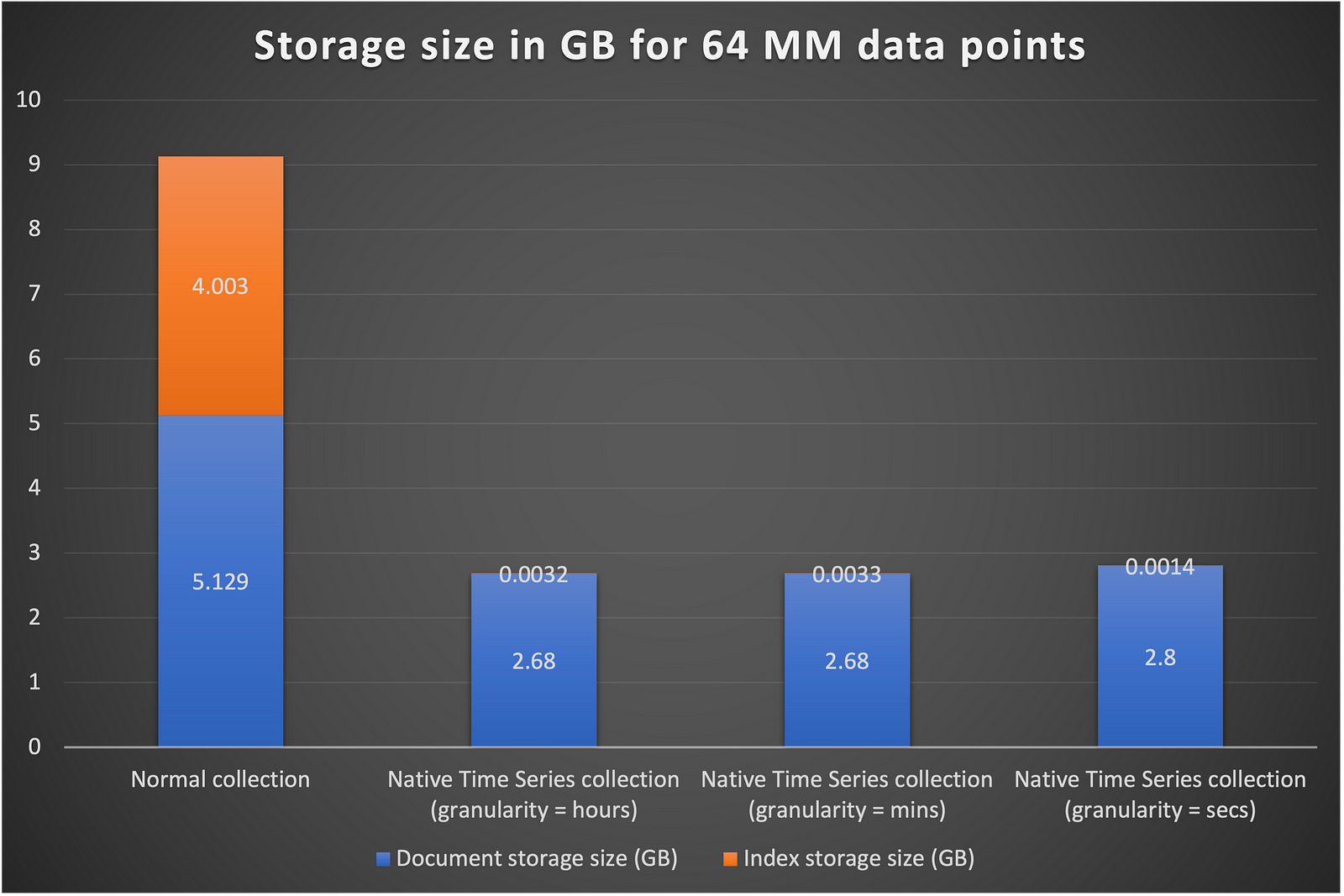
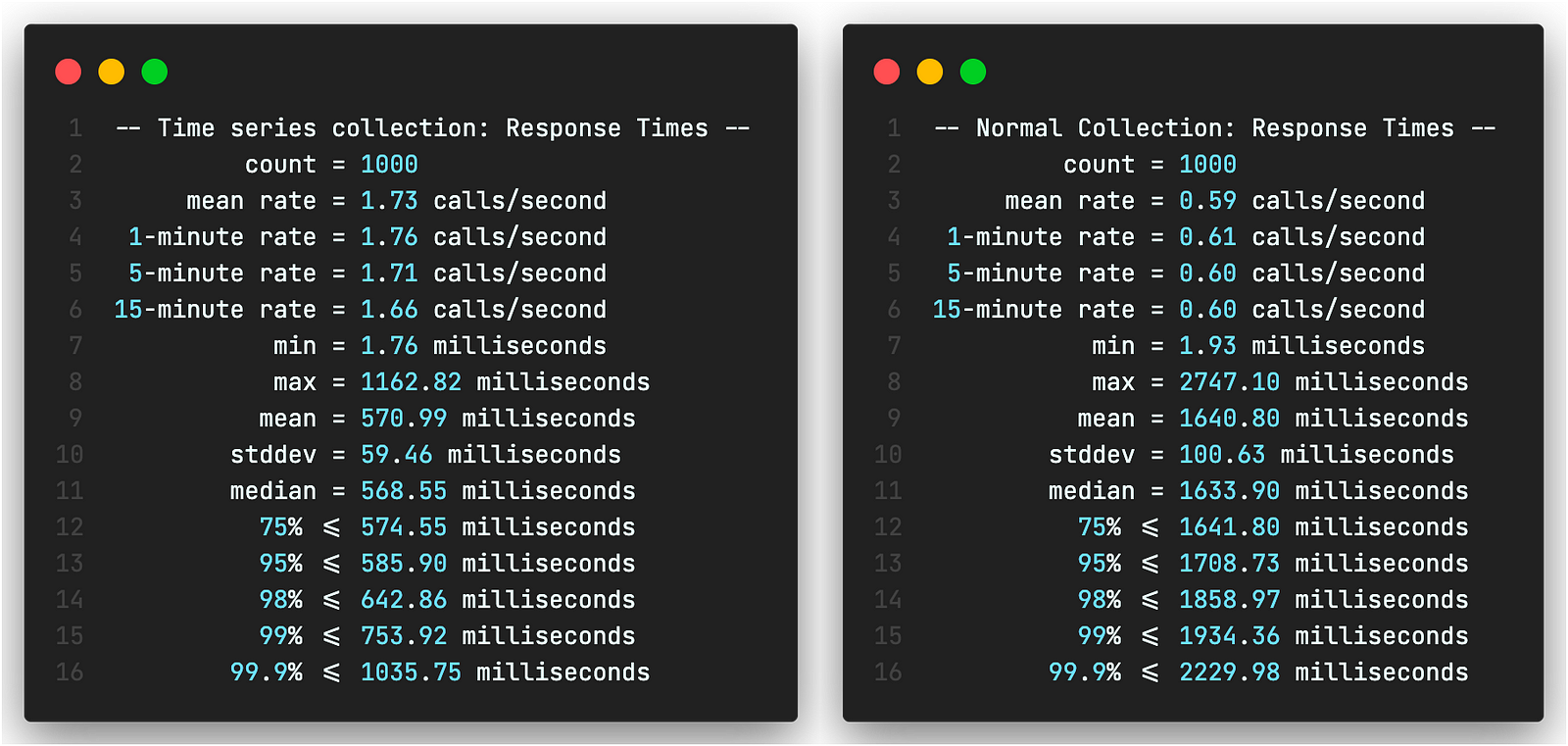
Document Storage size
When it comes to storage, you start to see significant optimization in the native time series collection. This can be attributed to
- Time series collections use “zstd” as default compression algorithm. Whereas normal collections use “snappy” as default.
- Time series collections store data in a more optimized manner in automatically managed buckets.
- Time series collections only store meta data once.
Index Storage size
The optimizations seen in index storage come from the fact that time series collections index groups of documents in stead of individual documents. These are “Clustered Indexes” .
Performance of native time series collection
Queries that look to filter out specific datasets such as the one below based on “server.id” and “reportTime” range result in similar performance characteristics.
On an average for 1MM queries it results in approximately 1 ms response time average.
This is as expected. Collections with indexes that satisfy a query criteria are expected to perform well. So does the native time series collection
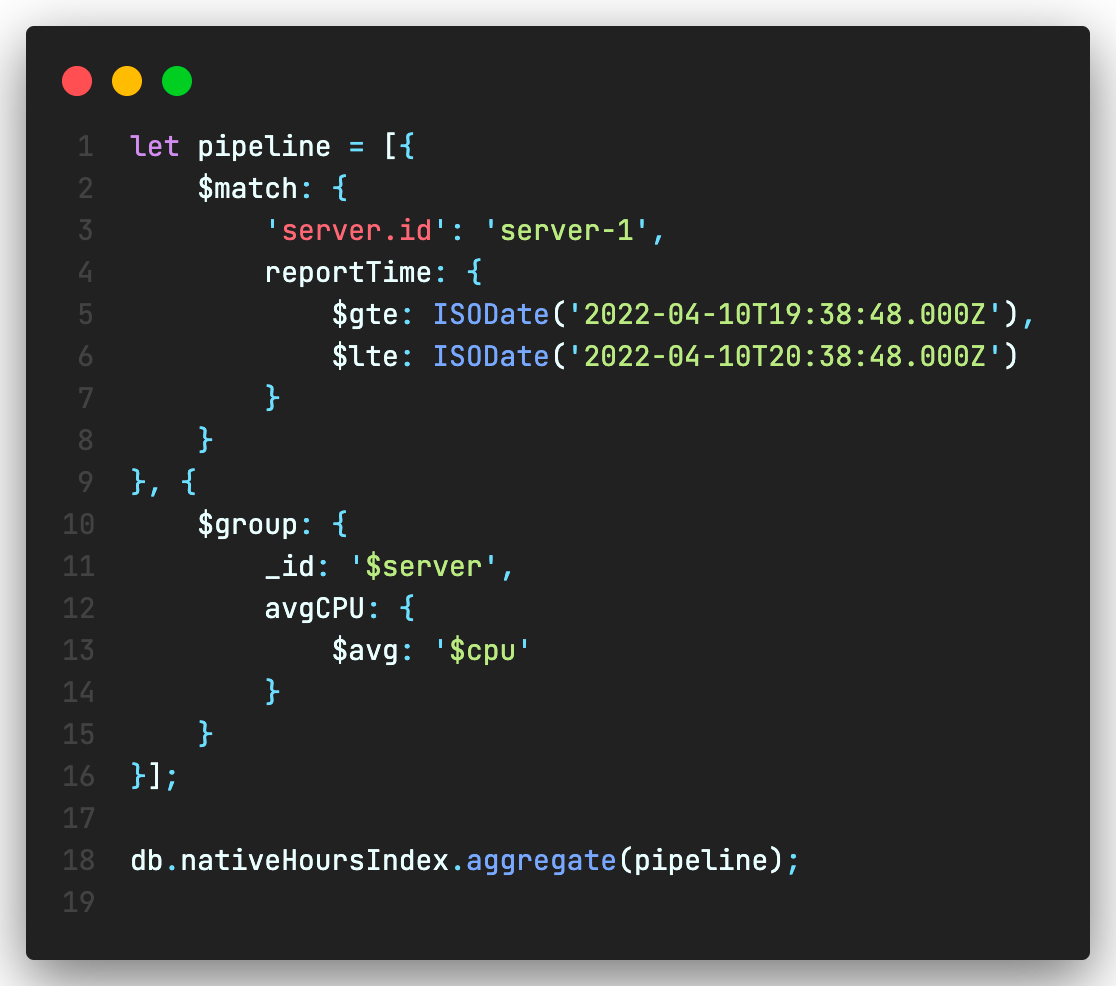
The following aggregation pipeline averages CPU readings by every hour across the time series. The native time series collection performs significantly better by almost 3 times compared to normal collection.
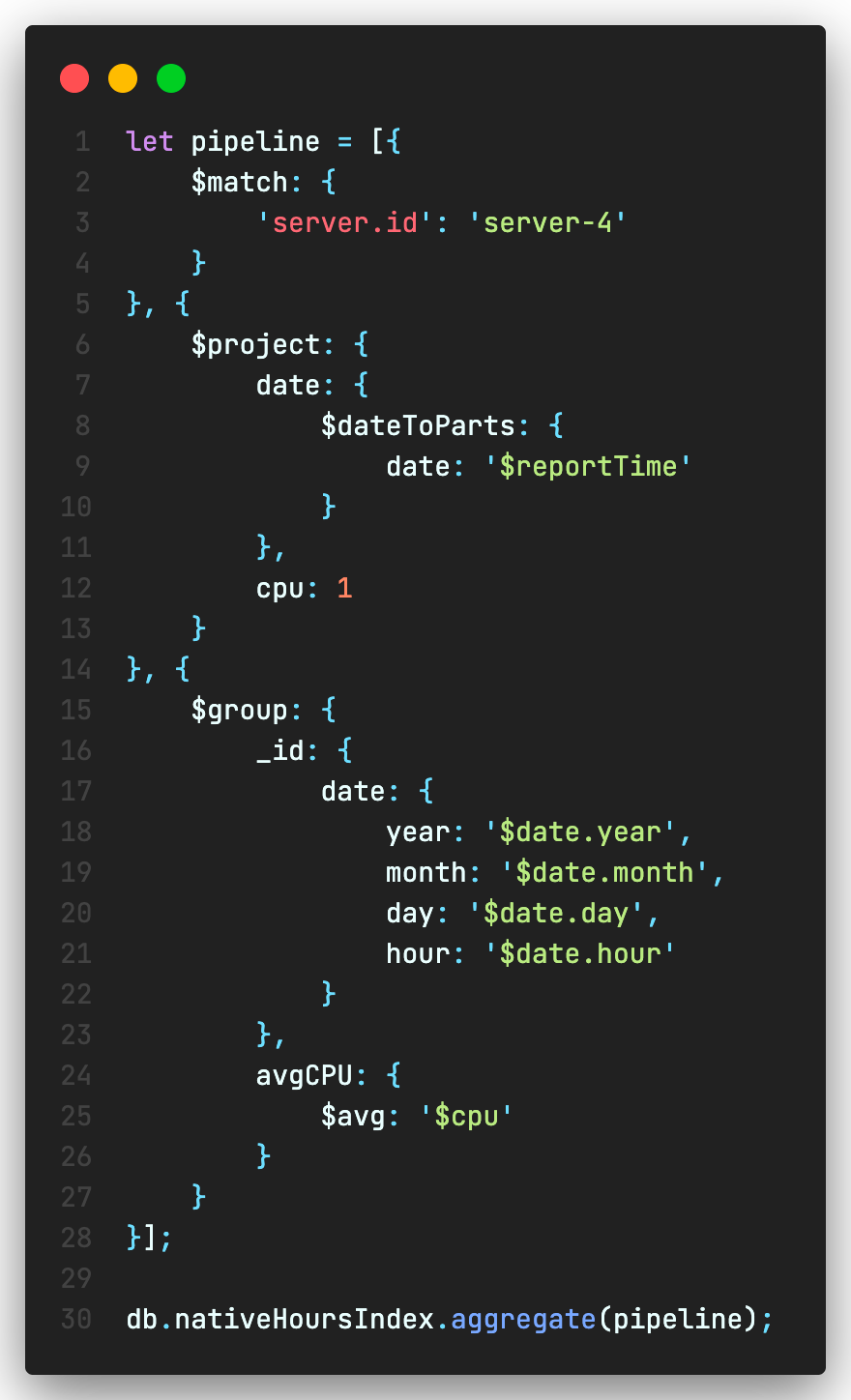
Analytical capabilities of native time series
MongoDB also added several time series analytical capabilities.
- $setWindowFields: is useful to perform analytics on time window of data.

- $dateTrunc: to truncate the dates to the appropriate granularity.

This can then be used to plot using MongoDB charts as follows:

and finally
- $densify and $fill: As we discussed earlier, one of the characteristics of time series data is that they may be irregular at times with gaps in the series. This may be due to sensor not reporting among other reasons. As part of time series analysis, the ability to extrapolate and fill the missing pieces is key. MongoDB added these functions in v5.3 to do just the same.
Let’s consider an example — I generated a range of data that is missing data for 2 hours in a 24 hour period. I plotted the same using MongoDB charts to visually display the missing data points.
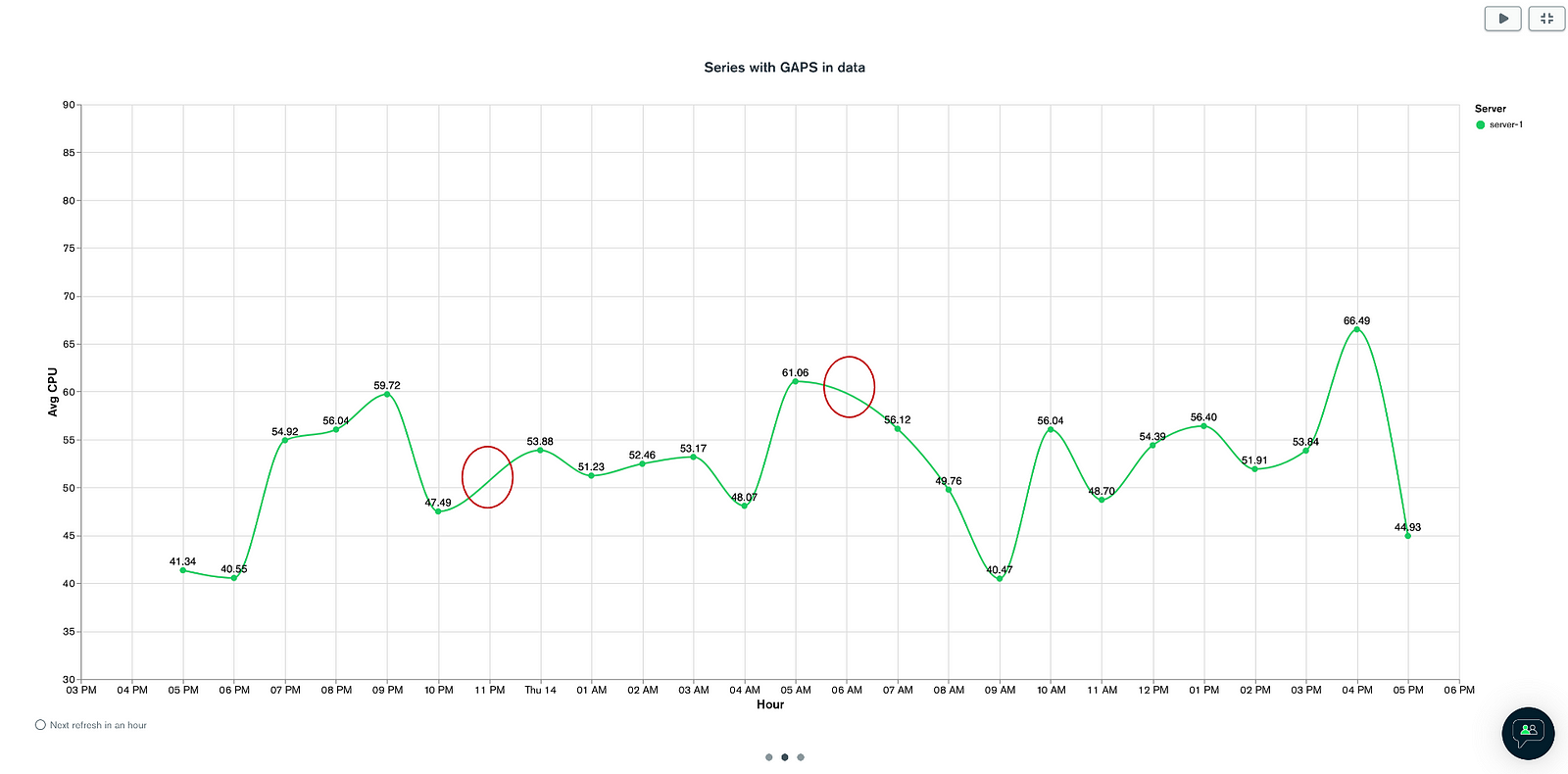
Now, I can make use of the $densify and $fill aggregation functions to fill in the missing pieces. $densify will add the missing documents. $fill will fill in the missing data points. We have option of filling with a “linear” value or with “locf” which fills the last known value. The aggregation pipeline for the same would like this.

The chart with gaps filled in would like this. You can see the extrapolated data. The correctness of such data is for analysis on another day. (Note: I had to create materialized view out of the data to chart it. MongoDB chart data sources don’t support $densify and $fill functions yet!)

- SMA and EMA functions: Time series data such as stock prices require us to smooth out the updates when doing analysis. MongoDB $avg provides Simple Moving Average of the series of data. $expMovingAvg provides Exponential Moving Average. These functions can be applied to
Time series collections: Purge and Archival
Whether it is data coming in from billions of sensors in IoT applications, product prices in eCommerce or payment transactions processing in FinTech applications, the need to manage hot and cold data is very important. Time series collections need ability to automatically archive old data or purge them when not needed.
MongoDB provides the following mechanisms
- expireAfterSeconds configured for time series collections allows MongoDB to automatically expire older documents
- Atlas online archive feature allows you to move data to cold tier storage for more cost efficient storage. While retaining ability to access it anytime.

Time series collections: Advantages
We have seen how time series collections work better than normal collections in specific niche areas of processing time series data in IoT, eCommerce, finance and other domains. The advantage of using time series collections can be summarized into the following:
- Flexible schema model — each data point can be different. Reporting of different measurements.
- Faster rate of ingestion — especially useful in the filed of IoT, high volume / velocity Fin Tech operations
- Smaller storage size — is of great help considering large volume of data streaming in
- Clustered indexes — resulting in efficient and small footprint indexes.
- Optimized IO — as a result of the optimized internal storage.
- Simpler TTL configuration — given most time series analysis is interested in recent data
- Specialized queries such as Window Functions to handle out of order and late data, $densify to fill missing data, aggregations such as SMA, EMA.
Time series collections: Limitations
Now time series collection is not a silver bullet to solve all problems. This capability fulfils a very specific need to optimally store and operate on time series data. For starters MongoDB has made the first general release with 5.0 and have been constantly making improvements including release of new features in 5.3. I would expect many more improvements in the months to come to further amplify the benefits seen above.
- The maximum size of a measurement document is 4 MB.
- Updates were introduced in 5.0.5. The query may only match on
metaFieldfield values. - Delete commands may only match on
metaFieldfield values. The delete command may not limit the number of documents to be deleted. - A time series collection can’t be created as a capped collection.
- he metaField doesn’t support the following index types — 2d, 2dsphere, text
- You can only set a collection’s timeField and metaField parameters when creating the collection. After creation these parameters can’t be modified.
- Once the granularity is set it can only be increased by one level at a time.
- Starting in MongoDB 5.0.6, sharded time series collections are supported. When using sharded time series collections, you cannot modify the granularity of a sharded time series collection.
What are the alternatives?
There are a number of TSDBs available in the market. You can categorize them into legacy database players who built time series capabilities on top of their existing engine and niche players that have purpose built time series database engines.

There are yet another class of products such as Prometheus, Splunk etc., that store time series log data for analytics.
It will be interesting to keep an eye out for how this space develops further.
And maybe at a future date, I would like to share my comparative analysis of various time series databases in a future blog.
Conclusion
IoT, eCommerce, FinTech, healthcare, infrastructure monitoring and other industries that generate petabytes of time series data are only going to increase manifold. Time series data analytics is the key to various use cases ranging from anomaly detection to prevent equipment failure, fraud detection in financial industry, early diagnosis of health conditions and many more.
Purpose built time series databases such as the one from MongoDB will be critical tools for these use cases.
Would like to hear your thoughts on your experience with TSDBs and what solutions you are looking to build on top of them.


